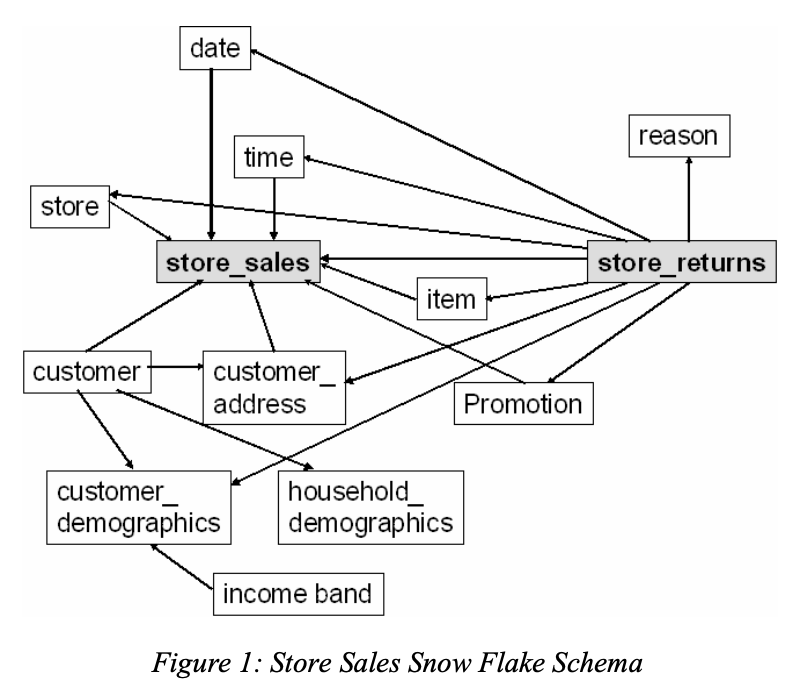
Author's note: this post has found it's way to the front-page of Hacker News -- follow along with the discussion there.
The SQL language made its first appearance in 1974, as part of IBM’s System R database. It is now nearly 50
years later, and SQL is the de facto language for operating the majority of industrial grade databases. Its
usage has bifurcated into two domains – application programming and data analysis. The majority of my 12
year career (data engineer and data scientist) has been concerned with the latter, and SQL is by far the
language that I have used the most. I love SQL for the productivity it has afforded me, but over time I’ve
also become aware of its many flaws and idiosyncrasies. My perspective is primarily from a practitioner’s
standpoint, and I have always been curious if those “real world” issues have more fundamental or theoretical
underpinnings. This brought me to A Critique of the SQL
Database Language, by mathematician and computer scientist CJ Date. Date was a former IBM employee, a
well known database researcher, and friend of EF Codd. The SQL standard has received many major updates
since this critique was first published, but which of those critiques are still valid today?
A Critique of the SQL Database Language was first published in November 1984 in The ACM SIGMOD Record. It
examines the dialect of SQL implemented by several IBM systems (SQL/DS, DB2, and QMF) which provided the
basis for the initial SQL standard. Having no direct experience with any of these systems, reading the SQL
examples from the paper is a bit like trying to read 17th century English – it has a stilting, unfamiliar
cadence that requires an extra bit of effort to understand. In the examples below, I’ll use the terms
SQL[1983] and SQL[2022] to distinguish between the older dialect, and what is available today. Use of the
unqualified term “SQL” means my comment could apply to both.
The paper consists of eight sections, each one describing a different category of criticism: lack of
orthogonality in expressions, lack of orthogonality in functions, miscellaneous lack of orthogonality,
formal definition, mismatch with host language, missing functions, mistakes, and missing aspects of the
relational model. In the rest of this post, I’ll go through each of those sections, describe the critique in
informal terms, and give my interpretation on whether the critique is still relevant.
Lack of Orthogonality: Expressions
Orthogonality with respect to programming languages means roughly that the constructs of the language are
like Lego blocks – a small number of basic pieces can be recombined in simple and intuitive ways. Lack of
orthogonality (again, informally speaking) means the language has lots of special cases and exceptions in
how the components can be put together, which make it complex to learn and unintuitive to use.
This section begins with a definition of table-expression, column-expression, row-expression, and
scalar-expression. Respectively, these are expressions in SQL that return a table, column, row, and scalar
value. In SQL[1983], the FROM clause of a SELECT statement was restricted to only
specifying table or view names, and not general table-expressions, i.e., subqueries or common-table
expressions (CTE). This made constructing nested expressions, one of the key features of Relational Algebra,
nearly impossible. Modern SQL provides the capability to reference a CTE or subquery in a FROM
clause, so this concern is mostly irrelevant today; however, the idea that a table-expression can take the
form of “tablename” in some contexts, but must be SELECT * FROM tablename in others is
interesting.
For example, why not allow the following expression as a legal statement:
tablename;
which would return identical results to:
SELECT * FROM tablename;
Both are table-expressions (statements that return a table), and thus should be allowed anywhere that
accepts a table-expression, e.g., the FROM clause of a SELECT statement, or a
statement itself.
While SELECT statements in SQL[1983] are not allowed in the FROM clause, they
are required as an argument to an EXISTS clause. Furthermore, the SELECT statement
here is required to be a column-expression (selecting only a single column) – a statement that returns a
table, a row, or a scalar will not work. When is a SELECT statement a table-expression, a
column-expression, a row-expression or a scalar-expression? The language itself provides no guidance here,
and it is wholly dependent on the query itself; e.g.:
SELECT a FROM tablename;
is a column-expression, but
SELECT a,b FROM tablename;
is a table-expression. This bit of arbitrariness still exists in SQL[2022].
Lack of Orthogonality: Functions
While some of the concerns in this section are mitigated by the introduction of subqueries and CTEs, a lot
of them still hold true today. Column functions in SQL take a column of scalars as input, and return either
a column of scalar values (e.g., the MD5 function or a type-casting function), or a single scalar (e.g.,
aggregate functions like SUM). The author argues here that since column functions take a column
of scalar values as input, any valid column-expression should be allowed. An example where this is not the
case is as follows:
SELECT SUM(val) FROM tbl
is allowed, but
SELECT SUM( SELECT val FROM tbl )
is not, even though SELECT val FROM tbl is a valid column-expression – it returns a single
column, val, from table tbl.
The key problem here is that the input to the SUM function in the first example is a column
name, but that column name alone does not define the column-expression. Instead, we must look at the context
(i.e., the full query) to understand that the “val” column comes from “table”. Said another way, in SQL,
F(X) is not dependent only on X, but on contextual information surrounding F:
SELECT SUM(amount) FROM purchases;
and
SELECT SUM(amount) FROM purchases WHERE 1 = 0;
Are two very different queries, even though the column-function invocation SUM(amount) is
identical.
This also makes it difficult to nest aggregations. Consider the following example: we have a database of
purchases for an ecommerce website, and want to retrieve (1) the total amount spent for each customer, and
(2) the average spend across all customers. SQL[1983] could not solve this in a single statement. SQL[2022]
can solve it with the use of CTEs:
WITH spend_per_customer AS (
SELECT
SUM(amount) AS customer_total
FROM purchases
GROUP BY customer
)
SELECT AVG(customer_total) FROM spend_per_customer
However, the following (arguably more natural) statement is not allowed:
SELECT
AVG(
SELECT SUM(amount) FROM purchases GROUP BY customer
)
In the above query, the inner SELECT is a column-expression (SELECT statement
returning a single column), and AVG is a function that takes a single column; however, the
above statement does not work in most databases. In Snowflake, the above query responds with the error
message “Single-row subquery returns more than one row”, which I find confusing, since the AVG
function clearly expects input of more than one row.
Another interesting consequence here is the necessity of the HAVING clause. The
HAVING clause is a favorite “gotcha” of SQL interviewers everywhere. Why and how is it
different from a WHERE clause? The answer is not immediately obvious to someone looking at SQL
for the first time. Specialized knowledge like this certainly serves a purpose as an indicator for
experience, but it can just as easily be seen as a deficiency of the SQL language. The HAVING
clause provides a scoping hint to a column-function to indicate that the function input must make use of the
GROUP BY clause. The author does not mince words here: “The HAVING clause and the
GROUP BY clause are needed in SQL only as a consequence of the column-function argument scoping
rules.”
The author also describes table-functions (functions that take a table as input, rather than just a
column), and laments several instances of arbitrary and non-orthogonal syntax. First, the
EXISTS function (takes a table-expression, returns a scalar) can only be used in a
WHERE clause, whereas orthogonality would dictate that it should be allowed anywhere that the
language accepts a scalar. Second, the UNION function is represented by an in-fix operator, and
since SQL[1983] did not allow arbitrary table-expressions in FROM clauses, it was impossible to
compute a column-function over a UNION of two tables. This problem is solved in SQL[2022], as
the following syntax is now legal:
SELECT
SUM(val)
FROM (
SELECT val FROM instore_purchases
UNION ALL
SELECT val FROM online_purchases
)
Lack of Orthogonality: Miscellaneous Items
This section contains a grab-bag of items related to functionality and implementation details of the
underlying systems – host/indicator variables, cursors, “long” fields (e.g., character fields with length
greater than 254). Some of the limitations are indeed very frightening (a “long” field could not be
referenced in a WHERE or GROUP BY clause!), but modern database systems are no
longer subject to these restrictions. Other items in this section have been addressed by updates to the SQL
standard. In no particular order, the following limitations are no longer applicable:
- Only simple expressions (column names) allowed in
GROUP BY
- NULL literal could not be used in places where a scalar constant was expected
- No concept of
UNION ALL
- Only possible to aggregate at one level with the
GROUP BY construct
While much of the discussion here is no longer relevant, the discussion of NULL values
remains as scary today as it ever was. Inconsistency in NULL handling gives rise to some truly
unexpected and frightening results, most notably in aggregate functions. Aggregate functions ignore
NULL values, leading to the unfortunate fact that for a column X with values
x1, x2, …, xn, x1 + x2 + … + xn != SUM(X)
(X1 + X2) != SUM(X1) + SUM(X2)
WITH v AS (
SELECT * FROM (
VALUES
(1, 5),
(null, 10)
) AS t (column1, column2)
)
SELECT
SUM(column1 + column2) AS sum_of_addition
, SUM(column1) + SUM(column2) AS addition_of_sum
FROM v;
which outputs
sum_of_addition | addition_of_sum
-----------------+-----------------
6 | 16
(1 row)
Formal Definition, Mismatch with Host Language, and Missing Functions
These three sections are taken together, as I found none of them to be of particular relevance to modern
databases, modern SQL, or analytical query processing.
Formal Definition: This section highlights areas where the developing SQL[1983] standard
either disagreed with the IBM implementation, or was not precise enough – cursor positioning, lock
statements, alias scoping rules, and more. I understand this section more to be a critique of the standard,
as opposed to the language itself. Furthermore, many of these issues (cursors, locks) are not as relevant to
analytical processing, and are thus not as interesting to me personally.
Mismatch with Host Language: Similar to the previous section, I found this one mostly
irrelevant. The author points out many differences between SQL and the host language (e.g., IBM PL/I) that
cause friction for the programmer. Today, there are so many potential host languages (Python, Ruby,
Javascript. Java just to name a few), each with their own idiosyncrasies, that it would be impossible for
SQL to conform to all of them. Technologies like LINQ aim to
address some of these concerns, but as with above, these primarily target application programming use cases.
Missing Functions: Most of the bullet points here are related to cursors and locking, which
I view as implementation-specific details related to underlying systems.
Mistakes
This section describes several things that the author views as simply a mistake in the language design.
Here again, NULL is the prime example:
In my opinion the null value concept is far more trouble than it is worth… The system should never
produce a (spuriously) precise answer to a query when the data involved in that query is itself imprecise.
At least the system should offer the user the explicit option either to ignore nulls or to treat their
presence as an exception
It is interesting to note that this was far from the consensus view, even amongst the original developers
of the relational model. EF Codd himself sanctioned the use of NULL in his 12 Rules (rule no. 3).
Other "mistakes" included are:
- Primary Key is specified as part of an Index as opposed to at table creation time.
- The reasoning here is that a Primary Key is really a logical property of a table, and should not be
intermingled with an index, which deals primarily with the physical access path of that data. Today,
most databases allow a
CREATE TABLE statement to include a Primary Key, so this concern
has largely been rectified.
-
SELECT * is undoubtedly convenient for interactive querying, but extremely prone to errors
when used in programs.
- Date argues that
SELECT * should only be allowed in interactive sessions. I largely
agree with this sentiment, but defining “interactive session” is by no means a trivial problem.
Aspects of the Relational Model Not Supported
This section is another list of miscellaneous items, unified by the fact that each of them prevented
SQL[1983] from truly being “relational”.
Primary Keys and Foreign Keys: Primary Keys could easily be ignored by SQL[1983] and
Foreign Keys did not even exist. While SQL[2022] does allow for Foreign Keys, and many databases enforce
referential integrity, SQL[2022] still does not fully understand the semantics of Primary Keys and Foreign
Keys. Two examples:
- When performing a
GROUP BY on the Primary Key of a table, and including other columns from
that table, because the Primary Key guarantees uniqueness, it is guaranteed that those other columns will
also be unique; however, SQL requires that those columns also be included in the GROUP BY.
- A join between a Foreign Key and its corresponding Primary Key could easily be implicit, but SQL still
requires the join condition to be explicitly written out.
Domains: Domain is another word for “type”. Type systems in SQL[1983] only permitted
primitive types (int, char, float, etc.). Today, Postgres provides support for user-defined types of
arbitrary complexity, as well as check-constraints that allow users to restrict primitive types to
acceptable values. Unfortunately, most OLAP data warehouses don’t support user-defined types, and SQL itself
doesn’t have much to say on the topic.
To take a simple example of how this can be dangerous, many databases in the wild have tables with integer
Primary Key ID columns. Clearly not all of the operations that are legal for integers should be allowed on
Primary Key columns – what does it mean to add, multiply, or divide two PK IDs? SQL, and most databases,
will happily let you perform these operations.
Relation Assignment: The critique here is a single sentence –
A limited form of relation assignment is supported via INSERT ... SELECT, but that operation
does not overwrite the previous content of the target table, and the source of the assignment cannot be an
arbitrary algebraic expression (or SELECT equivalent).
This is no longer true. Relation assignment can be done via CREATE OR REPLACE TABLE AS. With
subqueries and CTEs, the source can be any arbitrary algebraic expression.
Explicit JOIN, INTERSECT, and DIFFERENCE operators:
SQL[1983] did not support these. SQL[2022] does. JOIN was added to the SQL92 standard.
INTERSECT and MINUS are supported by most databases, and even if they aren’t, the
operators have semantically identical equivalents using JOIN.
Summary
While many of the critiques of SQL have been fixed by updates to the ANSI standard, many are still present.
Lack of orthogonality in many places still exists, which makes SQL clunky to learn and use; however, I
suspect the learning curve here is not actually all that high, judging by the number of people out there who
can write SQL. By contrast, missing components of the relational model and issues arising from
NULL values are likely the cause of many queries that look correct but provide wrong answers,
especially by folks who are confident in their ability to write queries, but unfamiliar with some of the
nastier traps.
Despite the improvements listed above, in a 2014
interview, CJ Date said “we didn’t realize how truly awful SQL was or would turn out to be (note that
it’s much worse now than it was then, though it was pretty bad right from the outset).” This quote leaves me
wondering – if Date himself were to write an updated critique, what would it look like? My best guess is
most of his criticism would revolve around further departures of SQL from the relational model, but specific
examples escape me.
SQL’s market dominance means every DBMS vendor is strongly incentivized to implement a SQL interface, and
every aspiring programmer must learn it. So does this mean that despite all its problems, we’re stuck with
SQL for good? I think SQL will continue to live on in some form for a very long time, probably even as the
dominant query language; however, I strongly believe there’s still room for the development of new query
languages that have learned the lessons of the past. Furthermore, I think the time is now better than ever
for such a language to succeed. My reasons for believing so are beyond the scope of this essay, perhaps a
good topic for the next one.